DOM
文档对象模型 (DOM) 是HTML和XML文档的编程接口。它给文档(结构树)提供了一个结构化的表述并且定义了一种方式—程序可以对结构树进行访问,以改变文档的结构,样式和内容。
DOM 提供了一种表述形式将文档作为一个结构化的节点组以及包含属性和方法的对象。从本质上说,它将web 页面和脚本或编程语言连接起来了。
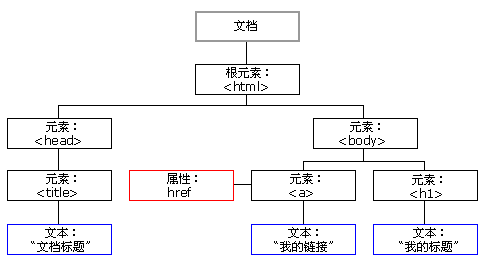
要改变页面的某个东西,JavaScript就需要获得对HTML文档中所有元素进行访问的入口。这个入口,连同对 HTML 元素进行添加、移动、改变或移除的方法和属性,都是通过DOM来获得的
document 对象
每个载入浏览器的HTML文档都会成为document对象。document对象包含了文档的基本信息,我们可以通过JavaScript对HTML页面中的所有元素进行访问、修改。
document对象常用属性
document对象有很多属性来描述文档信息,介绍几个常用的
doctype
在书写HTML文档的时候第一句一般都是doctype声明,可以通过document对象获取,没有则返回null
document.doctype; // <!DOCTYPE html>
document.doctype.name; // "html"
head、body
document.head;
document.body;
通过这两个属性何以分别获取文档的head,body节点
activeElement
activeElement属性返回当前文档中获得焦点的那个元素。
用户通常可以使用tab键移动焦点,使用空格键激活焦点,比如如果焦点在一个链接上,此时按一下空格键,就会跳转到该链接
documentURI、domain、lastModified
- documentURI属性返回当前文档的网址
- domain属性返回文档域名
- lastModified返回当前文档的最后修改时间
location
location属性返回一个只读对象,提供了当前文档的URL信息
// 假定当前网址为http://user:passwd@www.example.com:4097/path/a.html?x=111#part1
document.location.href // "http://user:passwd@www.example.com:4097/path/a.html?x=111#part1"
document.location.protocol // "http:"
document.location.host // "www.example.com:4097"
document.location.hostname // "www.example.com"
document.location.port // "4097"
document.location.pathname // "/path/a.html"
document.location.search // "?x=111"
document.location.hash // "#part1"
document.location.user // "user"
document.location.password // "passed"
// 跳转到另一个网址
document.location.assign('http://www.google.com')
// 优先从服务器重新加载
document.location.reload(true)
// 优先从本地缓存重新加载(默认值)
document.location.reload(false)
// 跳转到另一个网址,但当前文档不保留在history对象中,
// 即无法用后退按钮,回到当前文档
document.location.assign('http://www.google.com')
// 将location对象转为字符串,等价于document.location.href
document.location.toString()
虽然location属性返回的对象是只读的,但是可以将URL赋值给这个属性,网页就会自动跳转到指定网址。
document.location = 'http://www.example.com';
// 等价于
document.location.href = 'http://www.example.com';
title、characterSet
- title属性返回当前文档的标题,该属性是可写的
- characterSet属性返回渲染当前文档的字符集
readyState
readyState属性返回当前文档的状态,共有三种可能的值
- loading:加载HTML代码阶段,尚未完成解析
- interactive:加载外部资源阶段
- complete:全部加载完成
compatMode
compatMode属性返回浏览器处理文档的模式,可能的值为
- BackCompat:向后兼容模式,也就是没有添加DOCTYPE
- CSS1Compat:严格模式,添加了DOCTYPE
cookie
cookie是存储在客户端的文本,后续在客户端存储章节会介绍到
innerText
innerText是一个可写属性,返回元素内包含的文本内容,在多层次的时候会按照元素由浅到深的顺序拼接其内容
<div>
<p>
123
<span>456</span>
</p>
</div>
外层div的innerText返回内容是 "123456"
innerHTML、outerHTML
innerHTML属性作用和innerText类似,但是不是返回元素的文本内容,而是返回元素的HTML结构,在写入的时候也会自动构建DOM
<div>
<p>
123
<span>456</span>
</p>
</div>
外层div的innerHTML返回内容是 "<p>123<span>456</span></p>"
outerHTML 返回内容还包括本身
document对象常用方法
open()、close()
document.open方法用于新建一个文档,供write方法写入内容。它实际上等于清除当前文档,重新写入内容
document.close方法用于关闭open方法所新建的文档。一旦关闭,write方法就无法写入内容了。
write()
document.write方法用于向当前文档写入内容。只要当前文档还没有用close方法关闭,它所写入的内容就会追加在已有内容的后面。
document.open();
document.write("hello");
document.write("world");
document.close();
如果页面已经渲染完成再调用write方法,它会先调用open方法,擦除当前文档所有内容,然后再写入。
如果在页面渲染过程中调用write方法,并不会调用open方法。
需要注意的是,虽然调用close方法之后,无法再用write方法写入内容,但这时当前页面的其他DOM节点还是会继续加载。
除了某些特殊情况,应该尽量避免使用document.write这个方法。
Element
除了document对象,在DOM中最常用的就是Element对象了,Element对象表示HTML元素。
Element 对象可以拥有类型为元素节点、文本节点、注释节点的子节点,DOM提供了一系列的方法可以进行元素的增、删、改、查操作
Element有几个重要属性
- nodeName:元素标签名,还有个类似的tagName
- nodeType:元素类型
- className:类名
- id:元素id
- children:子元素列表(HTMLCollection)
- childNodes:子元素列表(NodeList)
- firstChild:第一个子元素
- lastChild:最后一个子元素
- nextSibling:下一个兄弟元素
- previousSibling:上一个兄弟元素
- parentNode、parentElement:父元素
查询元素
getElementById()
getElementById方法返回匹配指定ID属性的元素节点。如果没有发现匹配的节点,则返回null。这也是获取一个元素最快的方法
var elem = document.getElementById("test");
getElementsByClassName()
getElementsByClassName方法返回一个类似数组的对象(HTMLCollection类型的对象),包括了所有class名字符合指定条件的元素(搜索范围包括本身),元素的变化实时反映在返回结果中。这个方法不仅可以在document对象上调用,也可以在任何元素节点上调用。
var elements = document.getElementsByClassName(names);
getElementsByClassName方法的参数,可以是多个空格分隔的class名字,返回同时具有这些节点的元素。
document.getElementsByClassName('red test');
getElementsByTagName()
getElementsByTagName方法返回所有指定标签的元素(搜索范围包括本身)。返回值是一个HTMLCollection对象,也就是说,搜索结果是一个动态集合,任何元素的变化都会实时反映在返回的集合中。这个方法不仅可以在document对象上调用,也可以在任何元素节点上调用。
var paras = document.getElementsByTagName("p");
上面代码返回当前文档的所有p元素节点。注意,getElementsByTagName方法会将参数转为小写后,再进行搜索。
getElementsByName()
getElementsByName方法用于选择拥有name属性的HTML元素,比如form、img、frame、embed和object,返回一个NodeList格式的对象,不会实时反映元素的变化。
// 假定有一个表单是<form name="x"></form>
var forms = document.getElementsByName("x");
forms[0].tagName // "FORM"
注意,在IE浏览器使用这个方法,会将没有name属性、但有同名id属性的元素也返回,所以name和id属性最好设为不一样的值。
querySelector()
querySelector方法返回匹配指定的CSS选择器的元素节点。如果有多个节点满足匹配条件,则返回第一个匹配的节点。如果没有发现匹配的节点,则返回null。
var el1 = document.querySelector(".myclass");
var el2 = document.querySelector('#myParent > [ng-click]');
querySelector方法无法选中CSS伪元素。
querySelectorAll()
querySelectorAll方法返回匹配指定的CSS选择器的所有节点,返回的是NodeList类型的对象。NodeList对象不是动态集合,所以元素节点的变化无法实时反映在返回结果中。
elementList = document.querySelectorAll(selectors);
querySelectorAll方法的参数,可以是逗号分隔的多个CSS选择器,返回所有匹配其中一个选择器的元素。
var matches = document.querySelectorAll("div.note, div.alert");
上面代码返回class属性是note或alert的div元素。
elementFromPoint()
elementFromPoint方法返回位于页面指定位置的元素。
var element = document.elementFromPoint(x, y);
上面代码中,elementFromPoint方法的参数x和y,分别是相对于当前窗口左上角的横坐标和纵坐标,单位是CSS像素。
elementFromPoint方法返回位于这个位置的DOM元素,如果该元素不可返回(比如文本框的滚动条),则返回它的父元素(比如文本框)。如果坐标值无意义(比如负值),则返回null。
创建元素
createElement()
createElement方法用来生成HTML元素节点。
var newDiv = document.createElement("div");
createElement方法的参数为元素的标签名,即元素节点的tagName属性。如果传入大写的标签名,会被转为小写。如果参数带有尖括号(即<和>)或者是null,会报错。
createTextNode()
createTextNode方法用来生成文本节点,参数为所要生成的文本节点的内容。
var newDiv = document.createElement("div");
var newContent = document.createTextNode("Hello");
上面代码新建一个div节点和一个文本节点
createDocumentFragment()
createDocumentFragment方法生成一个DocumentFragment对象。
var docFragment = document.createDocumentFragment();
DocumentFragment对象是一个存在于内存的DOM片段,但是不属于当前文档,常常用来生成较复杂的DOM结构,然后插入当前文档。这样做的好处在于,因为DocumentFragment不属于当前文档,对它的任何改动,都不会引发网页的重新渲染,比直接修改当前文档的DOM有更好的性能表现。
修改元素
appendChild()
在元素末尾添加元素
var newDiv = document.createElement("div");
var newContent = document.createTextNode("Hello");
newDiv.appendChild(newContent);
insertBefore()
在某个元素之前插入元素
var newDiv = document.createElement("div");
var newContent = document.createTextNode("Hello");
newDiv.insertBefore(newContent, newDiv.firstChild);
replaceChild()
replaceChild()接受两个参数:要插入的元素和要替换的元素
newDiv.replaceChild(newElement, oldElement);
删除元素
删除元素使用removeChild()方法即可
parentNode.removeChild(childNode);
clone元素
cloneNode()方法用于克隆元素,方法有一个布尔值参数,传入true的时候会深复制,也就是会复制元素及其子元素(IE还会复制其事件),false的时候只复制元素本身
node.cloneNode(true);
属性操作
getAttribute()
getAttribute()用于获取元素的attribute值
node.getAttribute('id');
createAttribute()
createAttribute()方法生成一个新的属性对象节点,并返回它。
attribute = document.createAttribute(name);
createAttribute方法的参数name,是属性的名称。
setAttribute()
setAttribute()方法用于设置元素属性
var node = document.getElementById("div1");
node.setAttribute("my_attrib", "newVal");
等同于
var node = document.getElementById("div1");
var a = document.createAttribute("my_attrib");
a.value = "newVal";
node.setAttributeNode(a);
romoveAttribute()
removeAttribute()用于删除元素属性
node.removeAttribute('id');
element.attributes
当然上面的方法做的事情也可以通过类操作数组属性element.attributes来实现
HTMLCollection和NodeList
我们知道Element对象表示元素,那么多个元素的集合一般有两种数据类型
NodeList 对象代表一个有顺序的节点列表,HTMLCollection 是一个接口,表示 HTML 元素的集合,它提供了可以遍历列表的方法和属性
以下方法获取的为HTMLCollection对象
document.images //所有img元素
document.links //所有带href属性的a元素和area元素
document.anchors //所有带name属性的a元素
document.forms //所有form元素
document.scripts //所有script元素
document.applets //所有applet元素
document.embeds //所有embed元素
document.plugins //document.与embeds相同
document.getElementById("table").children
document.getElementById("table").tBodies
document.getElementById("table").rows
document.getElementById("row").cells
document.getElementById("Map").areas
document.getElementById("f2").elements //HTMLFormControlsCollection extends HTMLCollection
document.getElementById("s").options //HTMLOptionsCollection extends HTMLCollection
以下方法获取的为NodeList对象
document.getElementsByName("name1")
document.getElementsByClassName("class1")
document.getElementsByTagName("a")
document.querySelectorAll("a")
document.getElementById("table").childNodes
document.styleSheets //StyleSheetList,与NodeList类似
HTMLCollection与NodeList有很大部分相似性
都是类数组对象,都有length属性,可以通过for循环迭代
都是只读的
都是实时的,即文档的更改会立即反映到相关对象上面(有一个例外,document.querySelectorAll返回的NodeList不是实时的)
都有item()方法,可以通过item(index)或item("id")获取元素
不同点在于
HTMLCollection对象具有namedItem()方法,可以传递id或name获得元素
HTMLCollection的item()方法和通过属性获取元素(document.forms.f1)可以支持id和name,而NodeList对象只支持id
参考
Difference between HTMLCollection, NodeLists, and arrays of objects